2023. 9. 25. 11:26ㆍsnowflake
Snowflake는 클라우드 환경에 맞게 제작된 DBMS이다.
최근 회사에서 Snowflake 도입을 검토하고 있는데, 디테일한 내부 동작이 공개되어 있지 않아 자료 조사에 애를 먹고 있었다.
이에 Snowflake docs 및 fundemental 강의를 통해 Snowflake 내부 구조에 대해 공부했으며, 추후 Snowflake 도입을 검토하는 개발자들에게 도움이 되고자 이 글을 작성한다.
Snowflake Architecture

Snowflake는 AWS, Google Cloud, Azure 등의 클라우드 서비스에서 제공하는 기능들을 내부적으로 활용하고, 여기에 자체 개발한 쿼리 옵티마이저 등의 기술이 더해져 탄생한 DBMS이다.
Cloud Service Layer, Compute Layer, Storage Layer 3계층으로 구성되어 있으며, 각 계층의 역할은 다음과 같다.
- Cloud Service Layer
- 사용자에게 여러 가지 기능을 제공하면서, 기능 수행에 필요한 여러 가지 메타데이터를 관리하는 Snowflake의 뇌와 같은 역할을 한다.
- 쿼리 옵타마이저, 트랜잭션 관리, Automatic Clustering 등의 서비스를 담당한다.
- Compute Layer
- 사용자가 제출한 쿼리가 실제로 처리되는 계층이다.
- Virtual Warehouse (VWH) 라고 불리는 컴퓨팅 단위가 동작하는 계층이며, VWH는 여러 개의 가상 노드로 이루어진 하나의 클러스터이다.
- 쿼리 옵티마이저가 전달한 쿼리 계획을 VWH가 받아, 계획에 맞게 쿼리를 병렬 처리한다.
- Storage Layer
- 가장 밑단에 위치하는 계층으로, Snowflake table의 row가 저장되는 계층이다.
- Micro Partition이라 불리는 데이터 저장 공간 단위로 관리되며, 내부적으로 AWS S3, Google Cloud Storage, Azure Blob Storage로 구성되어 있다.
이 글에서는 Storage Layer의 내부 구조에 대해 자세하게 살펴본다.
Micro Partition
Snowflake에서는 데이터를 Micro Partition (이하 MP) 이라는 논리적인 공간에 저장한다.
MP는 Immutable (append-only) 한 특성을 지녔으며, hybrid columnar storage 라고 표현된다.
Hybrid Columnar Storage
기본적으로 table에 row가 삽입되면, 하나의 MP에 해당 row 내용이 저장된다.
MP 내부에 row가 어떻게 저장되는 걸까?
Snowflake의 공식 문서를 보면 Snowflake의 저장소는 hybrid columnar storage 라고 설명이 되어 있다.
columnar storage는 하나의 파일에 row 내용이 전부 저장되는 row storage 방식과 달리, 하나의 파일에 같은 column의 값들이 저장되는 방식을 말한다.

특정 column만 조회를 하는 유즈케이스에서, row storage를 사용하면 불필요한 column 데이터까지 모두 디스크 I/O가 필요하지만, columnar storage를 사용하면 조회할 column만 가져와 디스크 I/O 비용을 줄일 수 있다는 장점이 있다.
(columnar storage가 어떤 느낌인지만 살펴보고, 자세한 동작 방식은 이 글에서 다루지 않겠다.)
Immutable
Snowflake의 Storage Layer는 대중적인 클라우드 서비스의 저장소를 활용하고 있다.
이들은 모두 immutable (append-only) 한 특성을 지녔고, 자연스럽게 MP 또한 이 특성을 갖고 있다.
MP의 Immutable한 특성
AWS S3를 예로 들자면, 여기에 업로드된 파일을 직접 수정할 수 없다. 로컬에서 해당 파일의 내용을 변경하고, 변경된 파일을 재업로드 해야 한다.
Metadata
Snowflake의 Cloud Service Layer에서는 MP에 저장된 row 관련 정보를 메타데이터로 관리한다.

(위 그림에서는 각 column별 min, max 값만 표현되어 있다.)
- 각 column별 min, max
- 각 column value의 카디널리티 (distinct value number)
- ...
이 외에 다양한 메타데이터들이 있을 것으로 보이며, Storage Layer의 내부 구조를 이해하는 데에 "각 column별 min/max 값" 메타데이터가 중요하게 사용된다.
DML 연산
MP는 Immutable한 특성을 지니므로, 이미 MP에 저장된 row는 수정될 수 없다.
그렇다면 Snowflake에서 Update와 같은 연산은 어떻게 처리되고 있을까?
Snowflake에서 Update 쿼리가 수행되면 MP 하나를 새로 만들고, update 대상 row를 포함하는 MP의 내용을 복사한다.
이 때 대상이 되는 row는 변경된 내용으로 저장함으로써 update 연산이 수행된다.
아울러 각 테이블이 어떠한 MP들로 구성되어 있는지를 표현하는 table - mp 메타데이터가 존재하는데, 여기서 각 MP의 status를 관리하고 있다. update 연산으로 인해 새로 생성된 MP를 active 상태로 추가하고, 기존 MP를 delete 상태로 표기함으로써 update 연산이 완료된다.

위 그림을 예시로 update 연산의 과정을 살펴보자.
tableA 라는 테이블이 존재하고, 이 테이블은 MP1과 MP2로 구성되어 있다. table - mp 메타데이터에 tableA와 MP1, MP2가 매핑된 row 2개가 active 상태로 존재할 것이다.
이 상황에서 위와 같은 UPDATE 쿼리가 들어온다면, name = 'John' 인 row를 포함하는 MP1이 복사된 MP3가 생성되고, 이때 해당 row의 country 컬럼값은 'KR' 로 저장된다.
이후 table - mp 메타데이터의 tableA - MP1 row의 상태는 deleted 상태로 변경되고, 새로운 MP3의 메타데이터가 추가되면서 update 연산이 완료된다.
deleted 상태로 변경된 MP1은 바로 삭제되지 않고, Snowflake의 time travel 기능을 위해 정해진 기간 동안 보관된 후 삭제된다.
MP의 최대 크기가 (압축 기준) 10~16MB 이므로 단건의 MP 복사가 큰 부담이라고 말하기는 애매하지만, 그래도 다른 연산에 비해 무거운 작업인 건 명확하다.
아울러 뒤이어 설명하겠지만, Clustering 기능에도 update 연산은 좋지 않은 영향을 미친다.
Delete 연산 또한 위와 같은 방식으로 MP 복사를 통해 수행된다.
Clone
Snowflake는 MP 메타데이터를 활용해 빠른 성능의 테이블 복사를 지원한다.

논리적 테이블 tableA가 존재하고, 이 테이블이 MP1으로 구성되어 있다고 가정하자.
이 상태에서 tableA를 복사한 tableB를 만들 때, MP1을 복사하지 않고 MP1의 메타데이터 (MP-1) 을 복사한다.
이렇게 복제된 tableB로 SELECT 쿼리가 들어오면, MP1을 스캔하여 원하는 row를 조회할 수 있다.
Snowflake는 MP 메타데이터를 우선적으로 복사하여 빠른 시간 내에 테이블 복사본을 만들어낼 수 있다.
만약 tableB에 row를 삽입하는 쿼리가 들어오면 어떻게 될까?
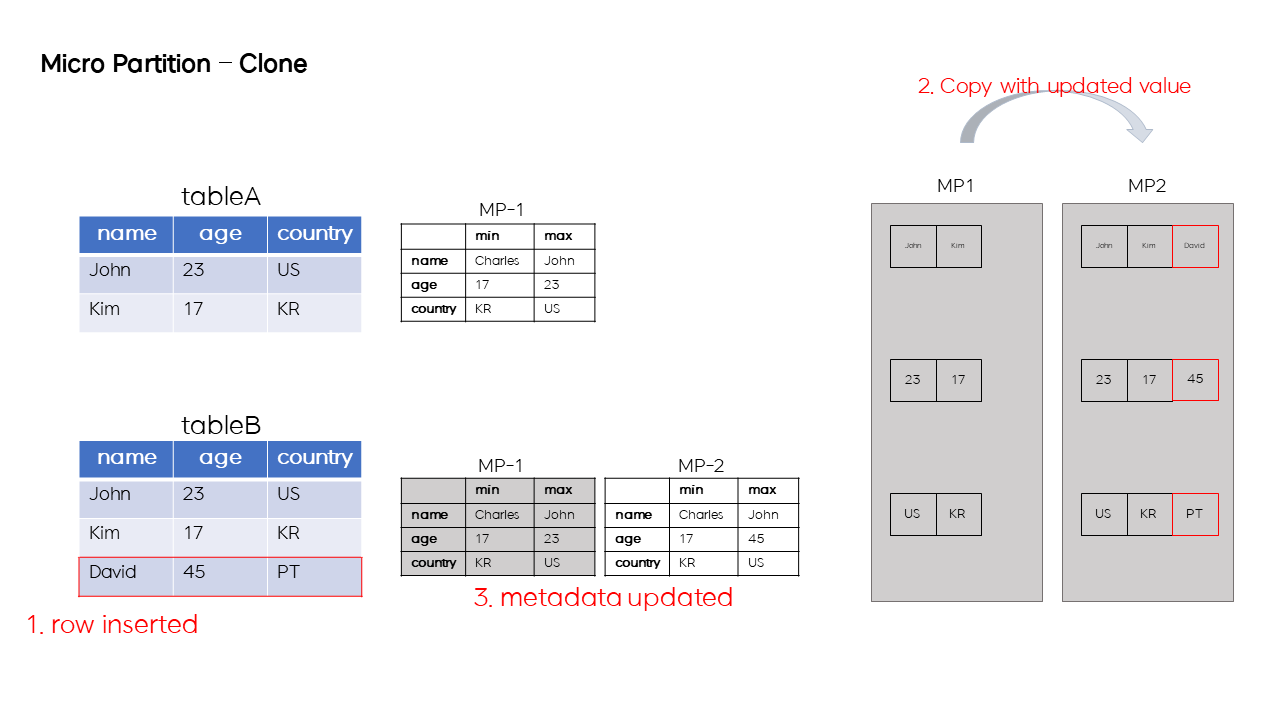
tableB에 row를 삽입하는 쿼리가 들어오면, MP1을 복사한 MP2가 생성되며 여기에 새로 삽입된 row가 저장된다.
아울러 tableB의 table - mp 메타데이터의 MP1이 delete 상태가 되고 MP2가 active 상태로 추가되면서, 복사된 테이블 tableB로의 Insert 연산이 완료된다.
위와 같은 매커니즘으로 빠른 테이블 복제가 가능하면서, 복제 테이블과 원본 테이블의 독립적인 운용이 가능하게 된다.
Query Pruning
Snowflake는 Index 기능을 지원하지 않는다.
그렇다면 특정 row를 조회하기 위해 매번 테이블을 구성하는 모든 MP들을 full scan 하는 걸까?
결론부터 말하자면, Index 기능을 일부 대체할 수 있는 내부 매커니즘을 가지고 있다.
MP의 min/max 메타데이터를 활용하여 스캔할 MP를 필터링하는 작업을 거치며, 이 작업을 query pruning이라 한다.

위 그림을 통해 query pruning 과정이 어떠한지 살펴보자.
MP 6개로 구성된 tableA가 존재하고, MP들의 min/max 메타데이터는 왼쪽 하단의 하얀색 표와 같다.
age = 23인 row의 name 컬럼값을 조회하는 쿼리가 들어왔을 때, query optimizer는 각 MP 메타데이터의 age 컬럼의 min/max 값을 확인하여 해당되는 MP 목록을 필터링한다.
필터링된 MP 목록을 VWH에 전달하고, VWH는 쿼리 계획에 맞게 해당 MP들을 스캔하여 조건에 부합하는 row의 name 컬럼 값 목록을 추출한다.
query pruning 성능은 쿼리 실행 시간과 직결된다. 즉, 더 적은 수의 MP를 스캔할수록 빠르게 쿼리가 처리된다.
직관적으로 생각해보면, A라는 컬럼을 WHERE절 조건으로 쿼리했을 때, 각 MP의 A 컬럼의 min/max 범위가 겹치지 않을수록 query pruning 성능이 좋아질 것을 짐작할 수 있다.
Clustering
어떠한 컬럼을 기준으로 MP의 min/max 범위가 겹치지 않고 MP에 고르게 저장되어 있다면, 이를 가리켜 "테이블이 잘 cluster된 상태" 라고 부른다.
clustering은 어떤 컬럼을 기준으로 MP의 min/max 범위가 최대한 겹치지 않게 정렬함을 의미한다.
clustering은 크게 natural clustering, automatic clustering으로 구분할 수 있다.
Natural Clustering
기본적으로 row는 테이블에 삽입되는 순서대로 MP에 저장된다.
즉, row의 삽입 순서와 비례하는 컬럼을 기준으로, 테이블은 자연스럽게 cluster된 상태가 된다.
(= 각 MP별 해당 컬럼의 min/max 범위가 거의 겹치지 않는 상태가 된다.)

위 그림을 보고 natural clustering이 무엇인지 살펴보자.
위 예시 테이블은 어떠한 캐릭터가 레벨업을 했을 때, 레벨업한 일자와 레벨업 후의 레벨이 적재되는 로그성 테이블이다.
위와 같이 5개의 row가 저장되었을 때, MP는 오른쪽 그림과 같고, 각 MP의 메타데이터는 왼쪽 하단의 하얀색 표와 같다.
이 상태에서, level_up_date 컬럼을 보면 MP에 정렬된 상태로 저장되어 있고, 이에 따라 MP별 level_up_date의 min/max 범위 또한 거의 겹치지 않음을 알 수 있다.
이 현상을 해석해보면
- row의 삽입 순서대로 MP에 저장된다.
- row 삽입 순서와 비례하는 컬럼의 min/max 범위는 MP 간 거의 겹치지 않게 된다. 즉, 해당 컬럼을 조건으로 조회할 때 query pruning 성능이 좋다.
- 만약 이러한 쿼리가 잦은 애플리케이션이라면, Snowflake를 우선적으로 검토해볼만 하다.
row 삽입 순서와 비례하는 컬럼은 시계열 컬럼 (ex. datetime) 이 대표적이다.
Natural Clustering은 Snowflake에서 지원하는 특정 기능이 아님을 기억하자.
row 삽입 순서와 비례하는 컬럼을 테이블 스키마에 포함시킴으로써, MP에 저장된 row들이 자연스럽게 해당 컬럼을 기준으로 정렬되게 만드는 기법이다.
Automatic Clustering
Cluster Key
Single Cluster Key
실제 현업에서, row 삽입 순서와 비례하는 컬럼을 조건으로 하는 쿼리보다 그 외의 컬럼을 조건으로 하는 경우가 더 많다.
원하는 컬럼으로 MP에 저장된 row가 정렬된 상태를 유지하도록 만들고 싶다면, 해당 컬럼을 cluster key로 설정하는 방법이 있다.
CREATE OR REPLACE TABLE tableA CLUSTER BY (age) (
name VARCHAR(10),
age NUMBER(4,0)
);위와 같이 DDL문에서 CLUSTER BY 절을 사용해 특정 컬럼을 cluster key로 설정할 수 있다.
cluster key가 선언된 테이블에는 Snowflake에서 제공하는 Automatic Clustering 기능이 주기적으로 동작하여, 해당 테이블을 구성하는 MP들이 cluster key 기반으로 정렬된 상태를 유지하게 만든다.

age 컬럼을 cluster key로 설정한 tableA가 존재하고, 현재 상태가 오른쪽 상단 표와 같다고 가정하자.
기본적으로 row가 테이블에 삽입되는 순서대로 MP에 저장되므로, MP에는 왼쪽 하단 그림과 같이 데이터가 저장되어 있을 것이다.
tableA는 cluster key가 설정되어 있으므로, 어느 계기로 인해 Automatic Clustering 기능이 트리거되면 오른쪽 하단과 같이 MP에 저장된 row가 age컬럼을 기준으로 정렬되게 된다.
Combined Cluster Key
여러 개의 컬럼을 묶어서 cluster key로 설정할 수도 있다. (편의상 복합 cluster key라고 명명하겠다.)
이 때 선언된 컬럼 순서대로 정렬되며, cluster key로 선언한 컬럼들을 동시에 조건으로 하는 쿼리에 가장 적합하다.
CREATE OR REPLACE TABLE tableA CLUSTER BY (name, age) (
name VARCHAR(10),
age NUMBER(4,0)
);
# 아래와 같은 쿼리 처리 시 query pruning 성능이 가장 잘 나온다.
SELECT name
FROM tableA
WHERE name = 'ngwoon' AND age = 23
name, age 컬럼을 cluster key로 설정한 tableA가 존재하고, 현재 상태가 오른쪽 상단 표와 같다고 가정하자.
Automatic Clustering이 트리거되면 MP에 저장된 row들은 오른쪽 하단과 같이 정렬된다. name 컬럼 기준으로 먼저 정렬되고, 그 다음 우선순위로 age 컬럼으로 정렬된 상태가 될 것이다.
복합 cluster key를 선언하면, 해당 컬럼들이 모두 조건으로 하는 쿼리나 첫 번째로 선언된 컬럼을 조건으로 하는 쿼리 시 query pruning 성능이 가장 좋다.
단, 두 번째 이상 순서로 선언된 컬럼은 사실상 정렬되지 않은 상태이므로, 해당 컬럼을 조건으로 하는 쿼리의 query pruning 성능이 좋아진다고 보장할 수 없다.
Materialized View
위 내용을 통해 복합 cluster key를 선언할 경우, 첫 번째 순서로 선언한 컬럼을 조건으로 포함하지 않는 쿼리는 query pruning 성능을 보장할 수 없음을 알게 되었다.
만약 첫 번째 순서로 선언한 컬럼을 조건으로 포함하지 않는 쿼리 빈도 또한 잦을 경우, 이 쿼리의 성능은 어떻게 향상시킬 수 있을까?
이 경우, 하나의 테이블에 복합 cluster key를 선언하는 대신 Materialized View (이하 MV) 를 활용하는 방법을 추천한다.
Snowflake의 View는 테이블 생성과 유사한 DDL로 생성할 수 있다.
일반 View를 대상으로 쿼리할 때마다 일반 View의 DDL이 수행되는 방식이라, 테이블을 대상으로 쿼리할 때보다 좋지 않은 성능을 보인다.
MV는 일반 View보다 조금 더 테이블에 가까운 View이다. MV 생성 시 독립적인 물리 공간에 MP들이 생성되어 row가 관리되고, MV 생성 시 사용된 테이블에 변화가 감지되면 이 내용이 MV에 자동으로 반영된다.
MV 생성 시 CLUSTER BY 절을 사용할 수 있다는 점을 활용하여 다양한 컬럼으로 각각 정렬된 MP 상태를 만들 수 있다.

위 그림을 보고 Materialized View를 어떻게 활용할 수 있는지 살펴보자.
col1을 cluster key로 설정한 base_table이 있고, 이 테이블을 기반으로 col2를 cluster key로 설정한 mv가 있다고 가정하자.
mv는 Materialized View이므로, base_table과 독립적인 MP들로 구성되어 있다.
mv를 생성할 때 base_table의 내용을 그대로 가져왔으므로, base_table과 mv에 저장된 row들은 동일하다. 다만 Automatic Clustering 기능이 동작할 때 정렬 기준으로 삼는 컬럼이 다르다.
예시 그림의 테이블에서 빨간 박스 표시된 row는 base_table과 MV에 모두 존재하지만, base_table에서는 col1 기준 정렬이므로 앞쪽인 MP1에 위치하고, mv에서는 col2 기준 정렬이므로 뒤쪽인 MP_N에 위치하게 된다.
컬럼 별 정렬의 이해를 돕기 위해 정렬 후 row의 위치가 MP1인지 MP_N인지로 표현했지만, 실제로 저렇게 앞 번호의 MP에 저장되는 방식으로 정렬되는 건 아니다.
cluster key가 col1이면 MP min/max 메타데이터가 col1 기준으로 최대한 겹치지 않게 row들이 재배치되고, cluster key가 col2면 min/max 메타데이터가 col2 기준으로 최대한 겹치지 않게 재배치된다.
Materialized View는 유용한 기능이지만, 독립적인 저장 공간이 필요하며 base_table의 변화를 감지하는 등 Snowflake에서 제공하는 내부 기능들이 지원되기 때문에 그만큼 비용이 발생한다.
natural cluster key 및 단일 cluster key 방식으로 커버할 수 없는지 충분히 검증하고, 반드시 필요한 상황에서만 사용하기를 권장한다.
Automatic Clustering 동작 과정
지금까지 cluster key가 무엇이고, 어떻게 설정할 수 있는지에 대해 살펴봤다.
cluster key를 설정하면 해당 컬럼을 기준으로 "정렬" 된 상태가 된다고 추상적으로 설명했는데, 여기서는 이 정렬이 어떻게 수행되는지 자세하게 알아본다.

Automatic Clustering은 Cloud Service Layer에서 동작하는 기능으로, cluster key가 설정된 테이블에 DML 연산이 누적되어 임계치를 넘어가면 트리거된다.
이 기능은 아래 두 가지 단계를 반복하는 방식으로 진행된다.
- 정렬할 파티션 선별 & 배치화
- 정렬 수행
Overlap Width & Overlap depth
automatic clustering은 어떠한 기준을 두고, 해당 기준이 충족되었을 때 정렬을 수행한다.
이 기준이 무엇인지를 먼저 살펴보자.
근본적으로 automatic clustering은 MP의 min/max 메타데이터를 활용하여 판단한다.
테이블을 구성하는 MP들의 cluster key 컬럼의 min/max 범위가 많이 겹칠수록, query pruning 성능이 좋지 않을 것이다.
MP 간 min/max 범위가 겹치는 정도를 overlap width 라고 하고, 그 중 가장 많은 수의 MP가 겹치는 부분의 깊이를 overlap depth라고 한다.

위 그림은 테이블을 구성하고 있는 MP들의 상태 네 가지를 표현하고 있다.
첫 번째 그림은 5개의 MP의 overlap width가 A-Z 이며, 가장 많이 겹치는 부분에서 MP 5개가 모두 겹치므로 overlap depth는 5이다.
세 번째 그림은 2개의 MP는 겹치지 않고, 나머지 세 개의 MP가 일부 겹치고 있다. 이 때 overlap width는 L-N 과 Q-S 이며, overlap depth는 2이다.
정리하면, 각 MP의 overlap width가 증가하면 overlap depth가 증가할 확률이 높아지고, overlap depth가 특정 기준치를 넘어가면 automatic clustering이 트리거된다.
automatic clustering은 기준치 아래로 overlap depth를 줄이는 방향으로 동작하며, overlap depth를 줄이기 위해서 overlap width를 줄여야 한다.
overlap width를 줄이기 위해 automatic clustering은 새로운 MP들을 만들고, 현존하는 row들을 정렬하여 새롭게 만든 MP들에 저장한다.
Sorting
automatic clustering은 정렬할 MP 들을 선별하고, 이를 배치화하여 실제 정렬을 수행한다.
배치화될 때 overlap width가 유사한 MP들이 같은 batch에 위치하도록 만들며, 각각의 배치는 Snowflake 내부 컴퓨팅 리소스에 의해 병렬적으로 처리된다.
아래 예시 그림을 통해 그 과정을 자세히 살펴보자.

왼쪽에 선별된 MP가 배치화되어 있다. 파란색 사각형 하나가 MP 하나를 의미하며, 적혀있는 알파벳은 해당 MP에 저장된 row의 cluster key 컬럼 값이라고 가정하자.
하나의 배치는 하나의 가상 노드에 의해 처리되며, 가상 노드 간 네트워크 통신을 거쳐 각 row를 어느 MP에 저장할지 결정한다.
Storage Layer의 왼쪽 MP들은 정렬 전 상태이며, 정렬된 후에는 오른쪽 MP들과 같은 상태가 된다.cluster key를 기준으로 정렬되었는데, 자세히 보면 엄격하게 정렬되지 않았음을 알 수 있다.
정렬은 여러 개의 가상 노드에 의해 병렬적으로 수행되므로, 모든 row가 엄격하게 정렬될 수 없다.automatic clustering의 목적은 엄격한 정렬이 아닌, 근사적인 정렬을 수행하여 각 MP간 overlap width를 최소화하는 것이다. 이는 곧 query pruning 성능 향상으로 이어진다.
Automatic Clustering Performance
automatic clustering은 테이블을 구성하는 모든 row를 복사하여 재정렬하는 작업이므로, 테이블의 크기가 클 경우 오버헤드가 굉장히 크다.
automatic clustering 과정 중 사용자의 DML 쿼리가 block되는 현상을 방지하기 위해, Snowflake에서는 두 가지 전략을 취하고 있다.
Incremental Steps
한 번에 소량의 MP를 배치화하여 정렬하고, overlap depth가 automatic clustering의 기준치 이하로 떨어졌는지 확인한다.
아직 overlap depth가 높다고 판단되면, 위 과정을 반복한다.
이와 같이 점진적으로 소량의 MP들을 정렬함으로써 테이블에 가해지는 오버헤드를 축소한다.

Optimistic Locks
만약 정렬 대상인 MP들에 lock을 걸고 시작한다면, (한 번에 소량의 MP들을 정렬하므로 처리 시간이 매우 길지는 않겠지만) 해당 MP들에 대한 DML은 정렬될 동안 block될 것이다.
이러한 block 현상을 최소화하기 위해 소량의 MP들을 정렬하여 새로 생성한 MP들을 commit하기 전, 정렬 대상 MP들이 DML에 의해 수정되었는지를 확인한다.
만약 수정되었다면, 작업한 내용을 버리고 다시 시도함으로써 사용자 DML이 block되는 기간을 정렬된 MP들을 반영하는 시간 동안으로 최소화한다.
Snowflake는 위와 같은 전략들을 적용하여 automatic clustering에 의한 block 현상을 최소화했다.
Data Analytics 블로그에 따르면, 1.3TB 테이블에 automatic clustering이 완료되기까지 약 4시간이 소요되는 성능을 보인다고 한다.
Automatic Clustering 주의 사항
automatic clustering은 특정 컬럼으로 MP들이 근사적인 정렬된 상태를 만들어 query pruning 성능을 향상시키는 유용한 기능이지만, 오버헤드가 있는 작업이며 얼마나 자주 수행될지 사용자가 예측하기 어려워 예상치 못한 금전적 비용을 초래할 수 있다.
이에 Snowflake 공식 문서 및 여러 사용자들이 제시한, automatic clustering을 적용하기 전 살펴보면 좋을 가이드를 소개한다.
1. 큰 규모의 테이블에 적용하라
테이블의 크기가 크지 않다면, query pruning 성능이 뛰어나지 않아도 쿼리 결과가 나오기까지 그리 긴 시간이 걸리지 않을 것이다.
다만 테이블의 크기가 TB 급의 큰 테이블에 대한 쿼리는 query pruning 성능에 따라 짧게는 수십 초, 길게는 몇 시간이 걸릴 수도 있다.
이러한 상황에서 쿼리 처리 시간을 줄이고 싶을 때 automatic clustering을 검토하면 좋다.
2. DML 쿼리가 적고, 조회 쿼리가 잦은 유즈케이스에 적합하다
DML은 데이터의 정렬 상태를 해친다. (특히 INSERT, UPDATE)
DML이 수행될수록 MP 간 overlap width가 증가할 확률이 높아지고, 이에 overlap depth가 증가하면서 automatic clustering이 그만큼 자주 트리거될 수 있다.
만약 DML이 특정 시간에 몰려있는 유즈케이스라면, 해당 시간에는 수동으로 automatic clustering을 껐다가, 잦아들면 다시 켜서 automatic clustering 효율을 높이는 방법도 고려해볼만 하다.
3. cluster key 적용 전 수동으로 정렬하라
이미 데이터가 존재하는 테이블에 cluster key를 새롭게 설정하거나 다른 컬럼으로 교체하는 상황도 있을 수 있다.
이 때, 곧바로 cluster key를 적용하기보다 이미 존재하는 데이터를 수동으로 정렬하고, cluster key를 적용하면 초기 오버헤드 및 automatic clustering 비용을 절약할 수 있다.
(수동 정렬이란, 애플리케이션 레벨에서 모든 row들을 cluster key 기준으로 정렬하여 다시 저장하는 것을 말한다.)
4. cluster key의 cardinality를 고려하라
cluster key의 cardinality도 automatic clustering과 관련된 중요한 고려 요소이다.

cluster key의 cardinality에 따라 MP들의 overlap width가 어떻게 될지 직관적으로 생각해보자. (row가 100개라고 가정)
cluster key의 cardinality가 1이라면, 테이블을 구성하는 모든 MP들의 min/max가 겹친다.
cluster key의 cardinality가 2이라면, 확률적으로 테이블을 구성하는 MP들 중 1/2의 min/max가 겹친다.
cluster key의 cardinality가 4이라면, 확률적으로 테이블을 구성하는 MP들 중 1/4의 min/max가 겹친다.
cluster key의 cardinality가 1억이라면, 테이블을 구성하는 MP들의 min/max가 겹칠 확률은 희박하다.
automatic clustering은 같은 cluster key 값을 가진 row들을 동일한 MP에 정렬하려는 방향으로 동작한다.
즉, cluster key의 cardinality가 커질수록, 각 MP의 min/max 범위가 커질 확률이 높다.
MP의 min/max 범위가 기준 이상으로 커지면, automatic clustering 중 정렬된 row들을 MP에 저장하는 과정에서 MP의 정상적인 크기 (10-16MB) 를 다 채우지 않은 상태로 다른 MP에 row를 저장하는 현상이 발생할 수 있다.
이상적인 크기보다 작은 MP들이 만들어지는 이 현상을 편의상 MP 파편화 라고 명명하겠다.
(automatic clustering의 내부 알고리즘이 공개되어 있지 않아 MP 파편화의 정확한 원인이 위에 설명한 내용이 아닐 수 있지만, 파편화가 발생할 수 있다는 건 사실이며 Snowflake 강사분께 들은 정보이다.)
automatic clustering은 여러 개의 가상 노드로 인해 병렬적으로 수행된다. 따라서 MP 파편화가 발생하면, 하나의 노드가 그만큼 더 많은 MP들을 담당해야 하며 자연스럽게 정렬을 위한 노드 간 네트워크 통신 비용이 증가한다.
이말인즉슨, MP 파편화가 발생한 상태에서 automatic clustering이 수행된다면 그만큼 정렬에 더 오랜 시간이 걸린다는 의미이다.


마무리
지금까지 Snowflake의 데이터 관리 방식에 대해 살펴보았다.
위 내용을 공부하며, Snowflake는 MP를 기반으로 하여 대용량 데이터 관리 및 Time Travel 기능 등 좋은 경쟁력을 갖춘 OLAP DB 라는 생각이 들었다.
다만 데이터 저장 방식이 일반적인 RDB나 NoSQL과는 사뭇 다르기 때문에, 이를 제대로 이해하고 사용해야 트러블 슈팅이 가능할 것 같다는 생각 또한 들었다.
이 글이 Snowflake를 검토 중인 개발자에게 도움이 되기를 희망하며, 혹여나 잘못된 내용이 있을 경우 편하게 댓글로 이야기하는 시너지가 났으면 하는 바람이다.
참고
https://medium.com/snowflake/automatic-clustering-at-snowflake-317e0bb45541
https://www.infoq.com/presentations/snowflake-automatic-clustering/
https://www.analytics.today/blog/snowflake-clustering-best-practice